Arm Announces Neoverse V2 and E2: The Next Generation of Arm Server CPU Cores
by Ryan Smith on September 15, 2022 8:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Neoverse
- ARMv9
- CMN-700
- Neoverse V2
- Neoverse E2

Just under four years ago, Arm announced their Neoverse family of infrastructure CPU designs. Deciding to double-down on the server and edge computing markets by designing Arm CPU cores specifically for those markets – and not just recycling the consumer-focused Cortex-A designs – Arm set about tackling the infrastructure market in a far more aggressive manner. Those efforts, in turn, have increasingly paid off handsomely for Arm and its partners, whom thanks to the likes of products like Amazon’s Graviton and Ampere Altra CPUs have at long last been able take a meaningful piece of the server CPU market.
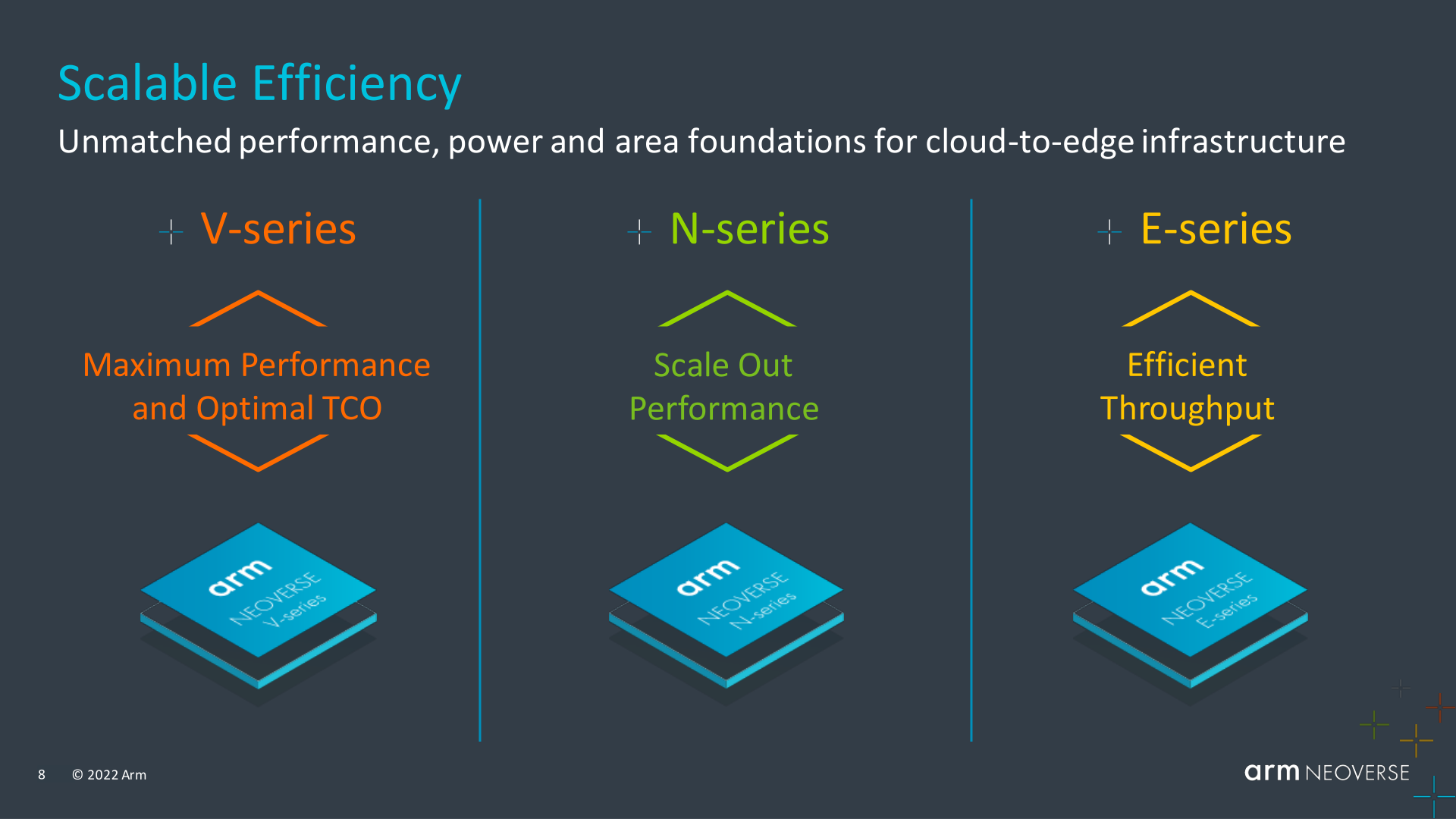
But as Arm CPUs finally achieve the market penetration that eluded them in the previous decade, Arm needs to make sure it isn’t resting on its laurels. Of the company’s three lines of Neoverse core designs –the efficient E, flexible N, and high-performance V – the company is already on its second generation of N cores, aptly dubbed the N2. Now, the company is preparing to update the rest of the Neoverse lineup with the next generation of V and E cores as well, announcing today the Neoverse V2 and Neoverse E2 cores. Both of these designs are slated to bring the Armv9 architecture to HPC and other server customers, as well as significant performance improvements.
Arm Neoverse V2: Armv9 Graces High-Performance Computing
Leading the charge for Arm’s new CPU core IP is the company’s second-generation V-series design, the Neoverse V2. The complete V2 platform, codenamed Demeter, marks Arm’s first iteration on their high-performance V-series cores, as well as the transition of this core lineup from the Armv8.4 ISA to Armv9. And while this is only Arm’s second go at a dedicated high-performance core for servers, make no mistake: Arm aims to be ambitious. The company is claiming that Neoverse V2 CPUs will offer the highest single-threaded integer performance available in the market, eclipsing next-generation designs from both AMD and Intel.
While this week’s announcement from Arm is not a full-on deep-dive of the new architecture – and, more annoyingly, the company is not talking about specific PPA metrics – Arm is offering a high-level look at some of the changes and features that will be coming with the V2 platform. To be sure, the V2 IP is already finished and shipping to customers today (most notably NVIDIA), but Arm is playing coy to some degree with what they’re saying about V2 before the first chips based on the IP ship in 2023.
First and foremost, the bump to Armv9 brings with it the full suite of features that come with the latest Arm architecture. That includes the security improvements that are a cornerstone feature of the architecture (and especially handy for cloud shared environments) along with Arm’s newer SVE2 vector extensions.
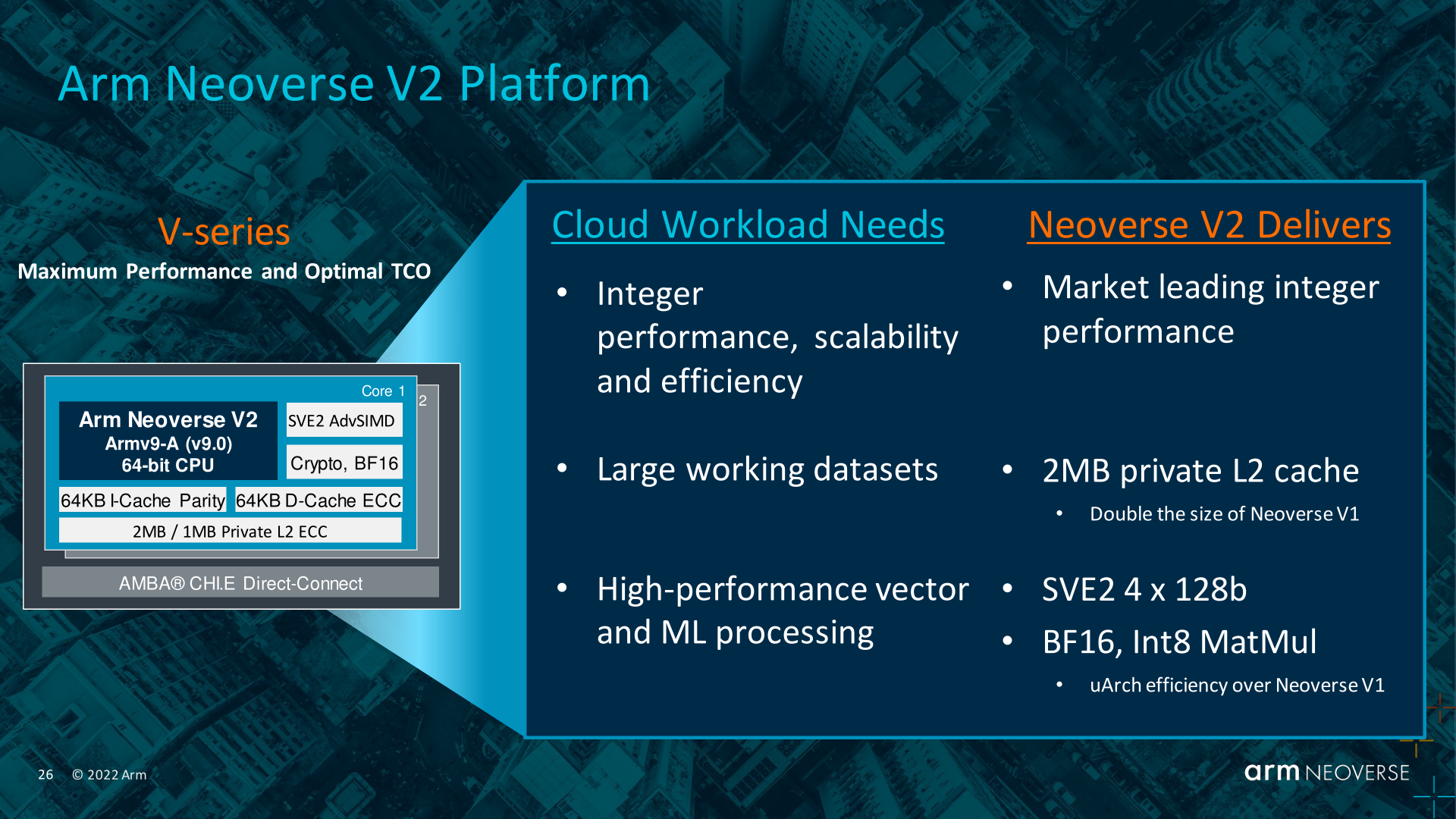
On the latter, Arm is making an interesting change here by reconfiguring the width of their vector engines; whereas V1 implemented SVE(1) using a 2 pipeline 256-bit SIMD, V2 moves to 4 pipes of 128-bit SIMDs. The net result is that the cumulative SIMD width of the V2 is not any wider than V1, but the execution flow has changed to process a larger number of smaller vectors in parallel. This change makes the SIMD pipeline width identical to Arm’s Cortex parts (which are all 128-bit, the minimum size for SVE2), but it does mean that Arm is no longer taking full advantage of the scalable part of SVE by using larger SIMDs. I expect we’ll find out why Arm is taking this route once they do a full V2 deep dive, as I’m curious whether this is purely an efficiency play or something more akin to homogenizing designs across the Arm ecosystem.
Past that, it’s likely worth noting that while Arm’s presentation slides put bfloat16 and int8 matmul down as features, these are not new features. Still, Arm is promising that V2’s SIMD processing will provide microarchitecture efficiency improvements over the V1.
More broadly, V2 will also be introducing larger L2 cache sizes. The V2 design supports up to 2MB of private L2 cache per core, double the maximum size of V1. V2 will also be introducing further improvements to Arm’s integer processing performance, though the company isn’t going into further detail at this point. From an architectural standpoint, the V1 borrowed a fair bit from the Cortex-X1 CPU design, and it wouldn’t be too surprising if that was once again the case for the V2, borrowing from the X2. In which case consumer chips like the Snapdragon 8 Gen1 and Dimensity 9000 should provide a loose reference on what to expect.

For the Demeter platform Arm will be reusing their CMN-700 mesh fabric, which was first introduced for the V1 generation. CMN-700 is still a modern mesh design with support for up to 144 nodes in a 12x12 configuration, and is suitable for interfacing with DDR5 memory as well as PCIe 5/CXL 2 for I/O. As a result, strictly speaking the V2 isn’t bringing anything new at the fabric level – even the 512MB of SLC could be done with a V1 + CMN-700 setup – but this does mean that the CMN-700 mesh and its features is now a baseline moving forward with V2.

The Neoverse V2 core, in turn, is going to be the cornerstone of the upcoming generation of high-performance Arm server CPUs. The de facto flagship here will be NVIDIA’s Grace CPU, which will be one of the first (if not the first) V2 design to ship in 2023. NVIDIA had previously announced that Grace would be based on a Neoverse design, so this week’s announcement from Arm finally confirms the long-held suspicion that Grace would be based on the next-generation Neoverse V core.

NVIDIA, for its part, has their fall GTC event scheduled to take place in just a few days. So it’s likely we’ll hear a bit more about Grace and its Neoverse V2 underpinnings as NVIDIA seeks to promote the chip ahead of its release next year.
Neoverse E2: Cortex-A510 For Use With N2
Alongside the Neoverse V2 announcement, Arm is also using this week’s briefing to announce the Neoverse E2 platform. Unlike the V2 reveal, this is a much smaller scale announcement, and Arm is only offering a handful of technical details. Ultimately, E2’s day in the sun will be coming a bit later on.
That said, the E2 platform is being delivered to partners with an eye towards interoperability with the existing N2 platform. For this, Arm has paired the Cortex-A510 CPU, Arm’s little/high-efficiency Cortex CPU core, and paired that with the CMN-700 mesh. This is intended to give server operators/vendors further flexibility by providing an alternative CPU core to the N2, while still offering the modern I/O and memory features of Arm’s mesh. Underscoring this, the E2 system backplane is even compatible with the N2 backplane.
Neoverse Next: Poseidon, N-Next, and E-Next
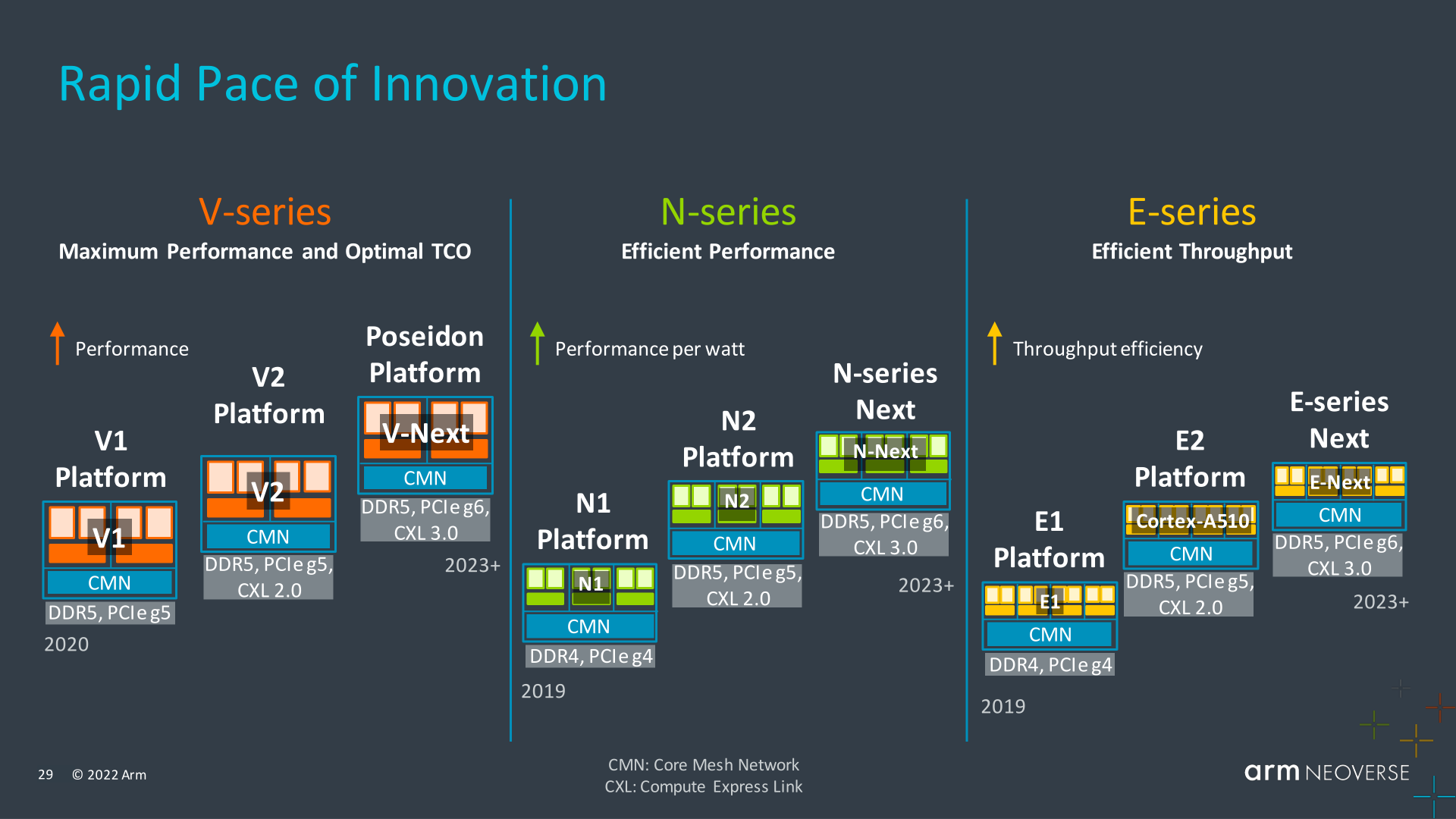
Finally, Arm’s announcement this week provides a glimpse at the company’s future roadmap for all three Neoverse platforms, where, unsurprisingly, Arm is working on updated versions of each of the platforms.
Notably, all three platforms call for adding PCIe 6 support as well as CXL 3.0 support. This would come from the next iteration of Arm’s CMN mesh network, which as Arm already does today, is shared between all three platforms.
Meanwhile, it’s interesting to see the Poseidon name once again pop up in Arm’s roadmaps. Going back to Arm’s very first Neoverse roadmap, Poseidon was the name attached to Arm’s 5mn/2021 platform, a spot since taken by N2 and V1/V2 in various forms. With V2 not landing in hardware until 2023, Poseidon/V3 is still years off, but there’s likely some significance to Arm keeping the codename (such as new microarchitecture).
But first out of the gate will be the N-Next platform – the presumable Neoverse N3. With the Neoverse N platform a generation ahead of the rest (N2 was first announced in 2020), it’ll be the next platform due for a refresh. N3 is due to be available to partners in 2023, with Arm broadly touting generational performance and efficiency improvements.








{kind=link}
39 Comments
View All Comments
mode_13h - Saturday, September 17, 2022 - link
What other core(s) have them?smalM - Monday, September 19, 2022 - link
Neoverse V1smalM - Monday, September 19, 2022 - link
All ARMv9 cores may have them too, but I'm not sure.Silver5urfer - Thursday, September 15, 2022 - link
Intel is toast until they get the SPR XEON out and it's delayed shame on Intel because they could have crushed ARM processors now AMD has to take over the x86 HPC market alone and tackle them. However once AMD releases Genoa with it's unprecedented scalable performance this ARM will again relegate itself to small subset.As for ARM vs x86 for clients, and many users x86 dominates it to the point of no return, simply because of Software and Hardware choices available plus a lot of forums as well for knowing things around. For eg any normal person can buy a decommissioned XEON and build their own Homelab while ARM cannot. And x86 PC destroys the locked down horrible garbage on mobile since the mobile ARM processors have battery and limited lifetime plus they get too old very very fast. An i7 2600K still runs, a very old Intel Core 2 Quad Q6600 can even run games if you patch the exe with the SSE4 mandatory requirements etc. So that's the beauty of x86 it's a real computer while ARM phones ? Look back and see how they fare, also the latest and greatest is a big joke, esp the fact that OSses both Android and iOS are crippled to death. Android used to be solid open but Google started to kill it inside out with PlayStore API mandates, Blacklisting, Scoped Storage and other garbage UI changes. ARM ends up in a landfill while a socketed x86 component can run latest OS without any BS.
Kangal - Thursday, September 15, 2022 - link
Prison Mike:The worst thing about prison was the... ARM Demeters.
vinay001 - Friday, September 16, 2022 - link
Well, many comments are comparing ARM with x86 in a generic way.But as of today, most of the ARM servers are being targeted for specific loads. In targeted scenarios Arm is indeed beating x86. Also, it has to be considered that electicty costs for servers is way more that hardware costs This is where Arm severs purpose for its major customers.
There are almost all hyperscalers now providing Arm instances. Be it Amazon, Mocrosoft, Google, Oracle or major Chinese ones.
Comparing Arm for gaming is again incorrect as its not the purpose that these Arm cores solve.
Intel and AMD both know this and they have low power cores in pipeline that will cater to such scenarios. But all hyperscalers seem to be developing in-house solutions also. Amazon is targeting 40-50% Graviton instances by 2025-26.
So Arm, this time, looks to have some traction.
mode_13h - Saturday, September 17, 2022 - link
> Comparing Arm for gaming is again incorrect as its not the purpose that these Arm cores solve.I know you mean gaming desktops/laptops, but plenty of gaming happens on phones. And that means most major game engines probably have well-optimized ARM backends. So, it seems like it shouldn't be a big leap for ARM to work its way into gaming-oriented chromebooks and eventually even min-desktops.
TeXWiller - Monday, September 19, 2022 - link
"This change makes the SIMD pipeline width identical to Arm’s Cortex parts (which are all 128-bit, the minimum size for SVE2), but it does mean that Arm is no longer taking full advantage of the scalable part of SVE by using larger SIMDs."I see this as taking full advantage of the scalable part of the SVE architecture. These units should be able to churn the 2048 bit vectors like the wider implementations, just a little slower.
Wilco1 - Monday, September 19, 2022 - link
It's scalable indeed, it just means your loops process less data per iteration. It does not need to be slower since an OoO core will execute multiple loop iterations in parallel (4x128 = 2x256 = 1x512).