AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
by Dr. Ian Cutress & Andrei Frumusanu on March 15, 2021 11:00 AM ESTDisclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPEC - Multi-Threaded Performance
Picking up from the power efficiency discussion, let’s dive directly into the multi-threaded SPEC results. As usual, because these are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2). For the new Zen3 Milan parts, as GCC 10.2 at the time didn’t have support for the new microarchitecture, we’re using the same Zen2 binaries as on Rome, as otherwise we’d have to rerun all numbers on all platforms with a newer GCC 11 baseline – something we will do in the future but out of the scope of this piece.
In terms of data-points, we’re comparing the new 7763 against a 7742, as well as the top socketed SKUs from the competition, including a Xeon 8280 (Equivalent to a Xeon 6258R), and Ampere’s Arm-based Altra Q80-33. It’s to be noted that the 7763 is a 280W part, and thus lands in higher than the other three chips, but we wanted to compare the top of the stack with the best available parts we had available for testing.
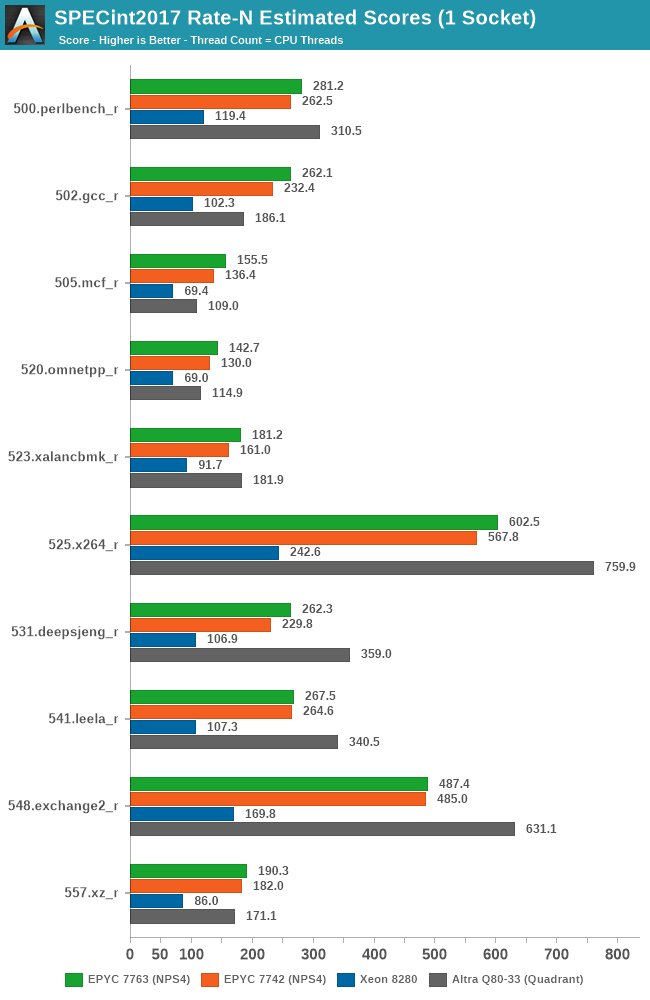
Generationally, the new 7763 does outperform the 7742 across the board, but generally the magnitude isn’t quite as large as you’d expect given the 40W higher TDP of the chip – a performance delta that gets even tighter when configuring the 7742 to a 240W cTDP.
Against the competition, AMD’s traditional adversary Intel doesn’t really stand a chance as the Milan chip is posting well over double the performance in almost all workloads.
The newer competition AMD should worry about is Ampere’s new Altra system – which currently still outperforms the top-end Milan based 7763 in several compute-heavy benchmarks by notably margins. In more memory-heavy workloads, the EPYC more easily beats the Altra due to having essentially 8x the total cache per chip at 256MB vs 32MB.
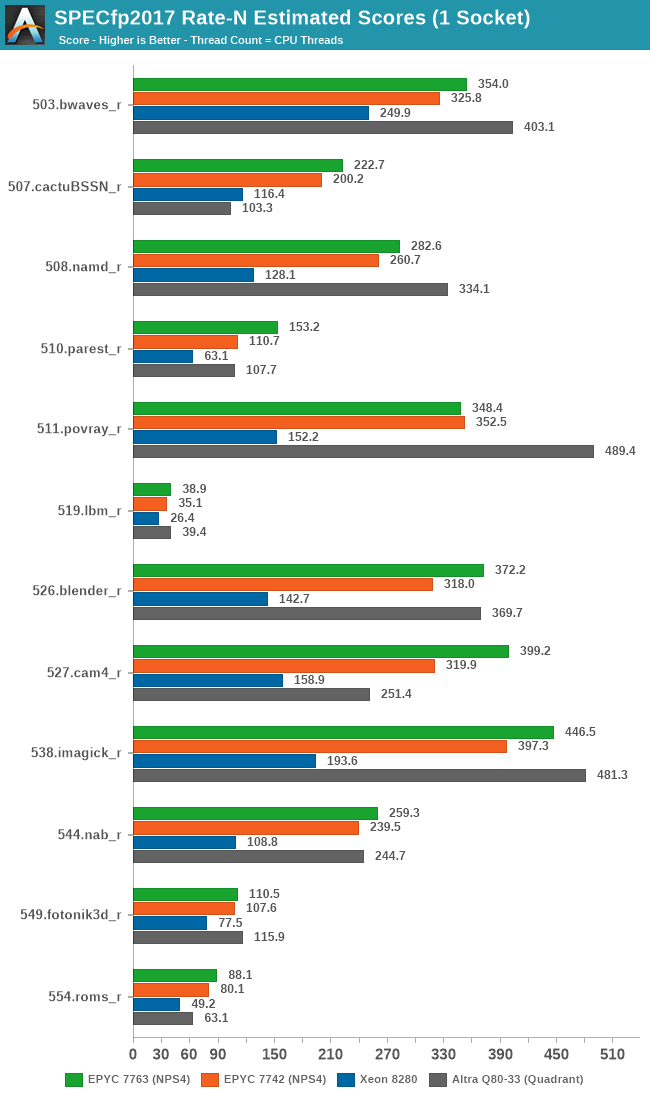
We’re seeing a similar story in SPECfp2017, more oriented towards HPC workloads. The one result that stands out here is 511.povray, in which the 7763 loses out to the previous generation 7742 due to the workload being more core-bound, and the Milan chip having a lesser effective thermal envelope available for the cores, even at the higher 280W TDP.
Intel’s 8280 again really isn’t a viable competition to AMD’s chips, with the Ampere Altra being a closer match for AMD’s EPYC, winning some, losing some.
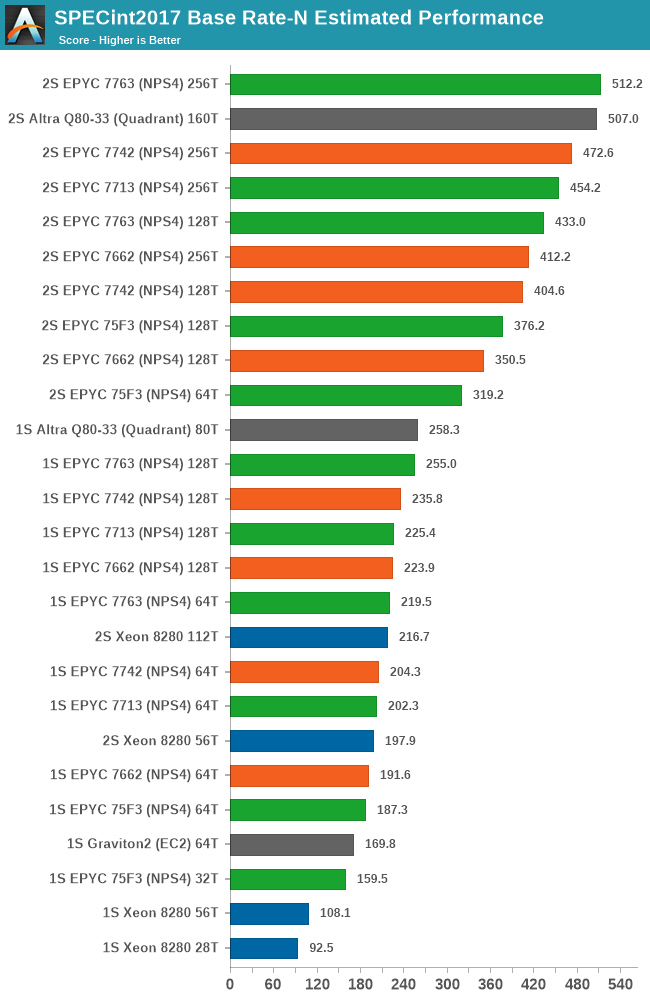
With Milan, AMD is now retaking the performance lead in SPECint2017, although by only a small margin.
Generationally, the EPYC 7763 is 12.8% faster than the 7742 – unfortunately we don’t have figures of the corresponding 280W 7H12 Rome part.
Comparing the 7713 against the 7742, things aren’t looking as great, as the new Milan part sees a 4% performance regression. It’s to be noted again that AMD had claimed the 7713 is a direct successor to the 7662, where it does fare 10% better, however that is a $900 cheaper part.
Amongst the rather luke-warm results of the top-stack Milan SKUs, one result that stands out more is the 32-core frequency optimised 75F3 SKU. Featuring only half the cores, the part still manages to easily compete amongst its 64 core siblings, showcasing 82% of the performance of a 7713. This has rather large implications for per-thread performance of this part which we’ll cover in a later page.
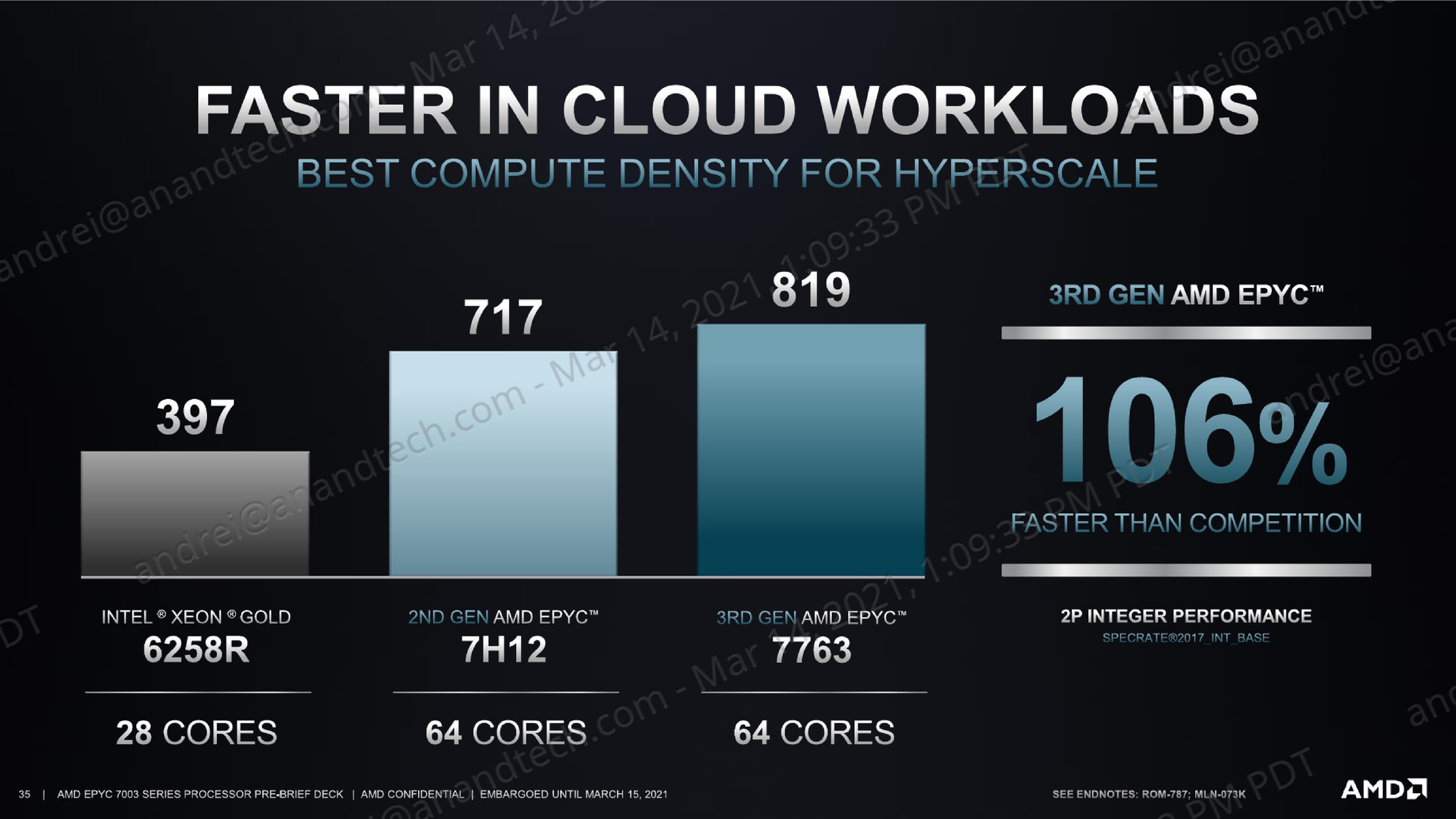
Although AMD’s presentation slides using totally different SPEC result numbers due to very different compiler and optimisation settings, the actual relative positioning we are getting in our internal results actually exceed that of what AMD is presenting, with the 7763 coming in with a +128% advantage over the Intel 8280, a part that’s performance equivalent to the 6258R.
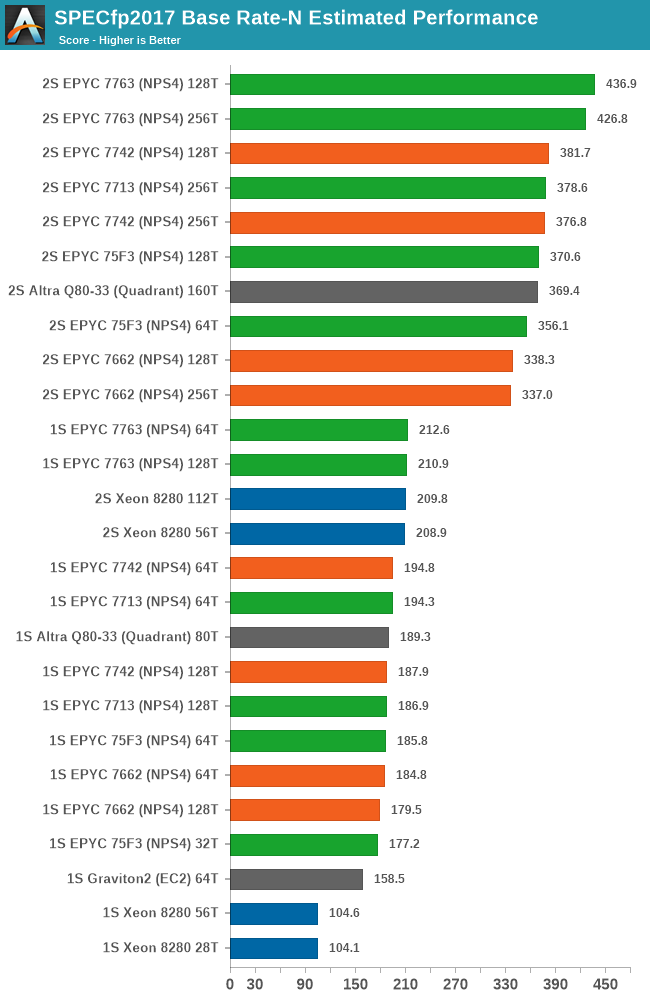
In the SPECfp2017 suite which is more representative of HPC workloads and has a focus more towards memory performance, AMD had always retained their performance leadership, and has now widened it with the new Milan generation. The 7763 performs 14.4% better than the Rome 7742, while the 7713 almost outperforms it by a margin of error.
It’s again the 75F3 which is actually stealing the show, as it manages 97.8% of a 7713, and 85.8% of a 7763 even though it has only half the cores.
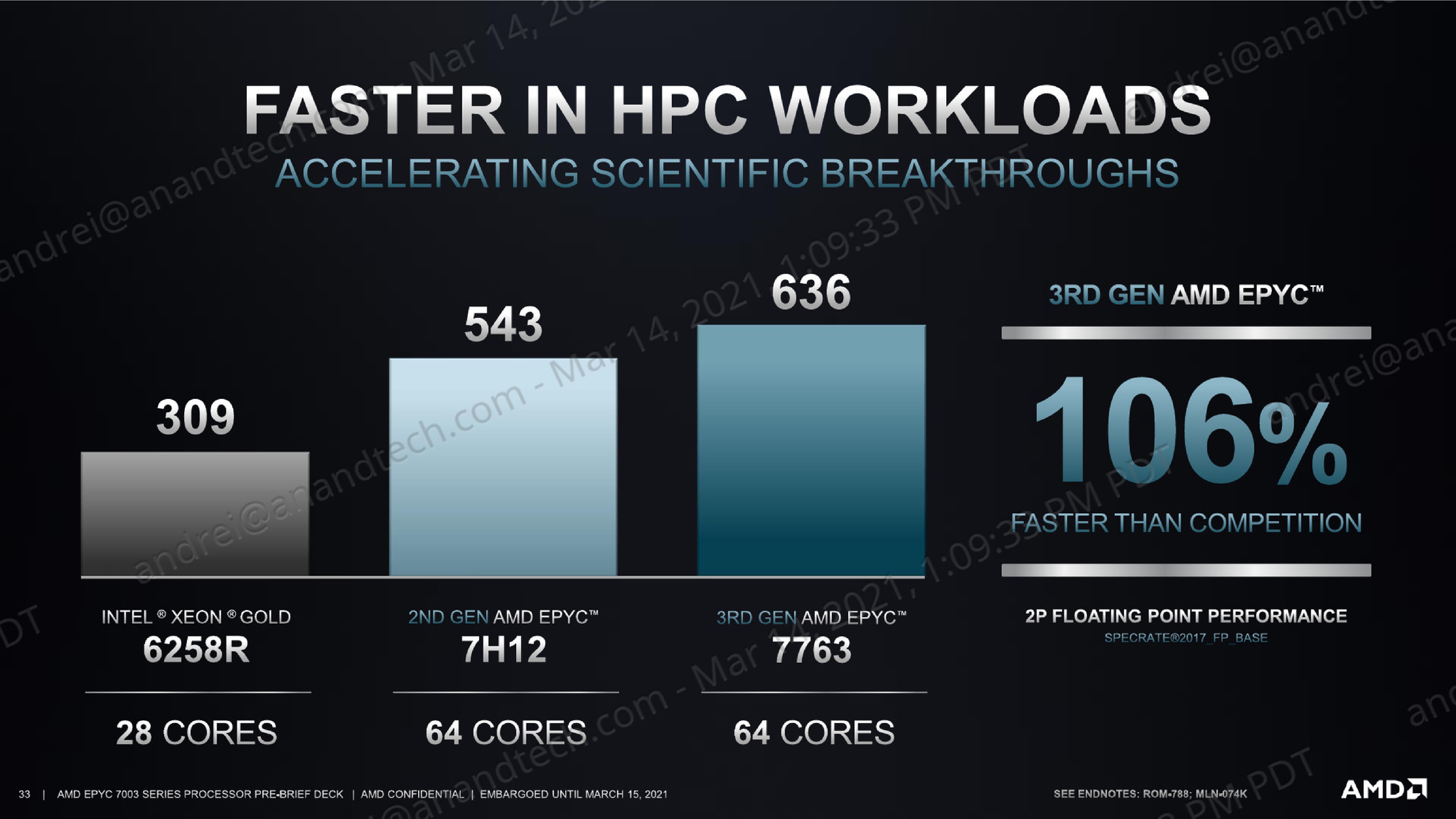
Against the competition and the figures AMD is showing, we’re measuring the 7763 outperforming the 8280 by 108% - near to the 106% the presentation material is showcasing. Intel should be able to make a larger leap with the next generation Ice Lake-SP server chips as the company moves from 6-channel to 8-channel memory, though we’ll have to see if that’s actually enough to catch up to AMD.








120 Comments
View All Comments
aryonoco - Tuesday, March 16, 2021 - link
Thanks for the excellent article Andrei and Ian. Really appreciate your work.Just wondering, is Johan no longer inlvolved in server reviews? I'll really miss him.
Andrei Frumusanu - Saturday, March 20, 2021 - link
Johan is no longer part of AT.SanX - Tuesday, March 16, 2021 - link
In summary, the difference in performance 9 vs 8 for (Milan vs Rome) means they are EQUAL. Not a single specific application which shows more than that. So much for the many months of hype and blahblah.tyger11 - Tuesday, March 16, 2021 - link
Okay, now give us the new Zen 3 Threadripper Pro!AusMatt - Wednesday, March 17, 2021 - link
Page 4 text: "a 255 x 255 matrix" should read: "a 256 x 256 matrix".hmw - Friday, March 19, 2021 - link
What was the stepping for the Milan CPUs? B0? or B1?mkbosmans - Saturday, March 20, 2021 - link
These inter-core synchronisation latency plots are slightly misleading, or at least not representative of "real software". By fixing the cache line that is used to the first core in the system and then ping-ponging it between to other cores you do not measure core-core latency, but rather core-to-cacheline-to-core, as expressed in the article. This is not how inter-thread communication usually works (in well-designed software).Allocating the cache line on the memory local to one of the ping-pong threads would make the plot more informative (although a bit more boring).
mode_13h - Saturday, March 20, 2021 - link
Are you saying a single memory address is used for all combinations of core x core?Ultimately, I wonder if it makes any difference which NUMA domain the address is in, for a benchmark like this. Once it's in L1 cache, that's what you're measuring, no matter the physical memory address.
Also, I take issue with the suggestion that core-to-core communication necessarily involves memory in one of the core's NUMA domains. A lot of cases where real-world software is impacted by core-to-core latency involves global mutexes and atomic counters that won't necesarily be local to either core.
mkbosmans - Saturday, March 20, 2021 - link
Yes, otherwise the SE quadrant (socket 2 to socket 2 communication) would look identical to the NW quadrant, right?It does matter on which NUMA node the address is in, this is exactly what is addressed later in the article about Xeon having a better cache coherency protocol where this is less of an issue.
From the software side, I was more thinking of HPC applications where a situation of threads exchanging data that is owned by one of them is the norm, e.g. using OpenMP or MPI. That is indeed a different situation from contention on global mutexes.
mode_13h - Saturday, March 20, 2021 - link
How often is MPI used for communication *within* a shared-memory domain? I tend to think of it almost exclusively as a solution for inter-node communication.