Intel Unveils Meteor Lake Architecture: Intel 4 Heralds the Disaggregated Future of Mobile CPUs
by Gavin Bonshor on September 19, 2023 11:35 AM ESTCompute Tile: New P (Redwood Cove) and E-cores (Crestmont)
The compute tile is the first client-focused tile to be built on the Intel 4 process technology. It houses the latest-generation P-cores and E-cores, both of which are based on newer and updated architectures. The P-Cores are officially called Redwood Cove, while the E-Cores are Crestmont. Intel also claims that power efficiency is greatly improved from previous generations, combined with its 3D Foveros packaging and offloading less performance-critical elements such as the SoC, media, and graphics onto other tiles. Intel also uses the same ring fabric to interconnect all the tiles to reduce power and latency penalties across the entirety of the chip.
One thing to note with the new core architectures, including Redwood Cove (P-core) and Crestmont (E-core), is that Intel was very light on disclosing many of the finer details. While we got the general blurb of 'it's better than this and has better IPC performance than the last gen,' Intel has omitted details such as L3 cache, whether there's L4 cache through Intel's "Adamintine" hierarchy, and disclosing decoder widths within the cores. As such, Intel hasn't provided enough details for us to do a full architectural deep dive of Redwood Cove or Crestmot, but more an easy look to see what's new and how it's implemented.

Looking at some of the new changes to Meteor Lake, one of the most notable is the introduction of the new Redwood Cove P-core. This new P-core is the direct successor to the previous Golden Cove core found in the 12th Gen Core (Raptor Lake) processors and is designed to bring generational improvements. As expected, Meteor Lake brings generational IPC gains through the new Redwood Cove cores. The Redwood Cove core also has increased bandwidth for both cache and memory. The performance monitoring unit has also been updated to enhance monitoring, and one of the standout features of the new P-Core is the enhanced feedback provided by Intel's Thread Director, which aids in optimizing core performance and directing workloads to the right cores.

Another inclusion is the new Cresmont-based E-cores, which also benefit from generational IPC gains, and they keep the CPU-based AI acceleration through Vector Neural Network Instructions (VNNI) as seen on Raptor Lake (13th Gen) and Alder Lake (12th Gen). Intel claims improvements over the previous gens, although they haven't provided anything to substantiate this.
However, Intel states what it means by improvements: "Architectural simulation vs. Gracemont architecture across a broad set of workloads. VNNI improvements based on doubling the number of VNNI ports. Results may vary." This is a very roundabout way of saying we've doubled the number of AVX2 VNNI ports, but they haven't given us any figures, and with Raptor Lake, not all SKUs had support for the VNNI instruction set. They haven't told us whether or not this is now a feature of the Crestmont E-core itself or if it's, again, SKU-dependent.
This is designed to bolster the user experience when using AI applications and running AI-based workloads, although the NPU on the SoC tile is predominately more suited for these. Like the P-Cores, the E-Cores also benefit from enhanced Thread Director feedback, which provides better granular control and optimization. Workloads that aren't as intensive can be offloaded onto the new Low Power Island E-cores, which are embedded into the SoC tile.

One area where Intel is promising major improvements and optimizations is through Thread Director. The Alder Lake (12th Gen) and Raptor Lake (13th Gen) architecture introduced a nuanced approach to scheduling. Under Alder/Raptor work was assigned a quality-of-service (QoS) ranking, and higher priority work was allocated to P-cores for more demanding and intensive workloads, while lower-ranked workloads are directed to E-cores, primarily to save power.
In cooperation with Microsoft Windows, Intel is bringing new enhancements and refinements into play for Meteor Lake. Meteor Lake's SoC tile LP E-cores represent a third tier of service, and Thread Director will try to keep work there first. Then, if threads need faster performance, they can be moved to the compute tile, accessing the faster, full-power E-cores, and at the top, the P-cores. This gives the chip better overall workload distribution in terms of power efficiency. Moreover, Meteor Lake's strategy to periodically move highly demanding tasks to the P-cores that can benefit from the higher performance levels offers a dynamic approach to thread scheduling.
Overall, this is designed to improve power efficiency through Meteor Lake, giving it more versatility over Raptor Lake regarding task scheduling. The flip side is that, on paper, Meteor Lake is a more efficient platform through these enhancements than Raptor Lake, especially in scenarios requiring rapid adjustments to fluctuating workloads and through those lighter workloads that can be offloaded onto the LP E-cores within the SoC.
Compute Tile: Intel 4 with EUV Lithography
The entirety of the compute tile, including the P and E-cores, is built using the Intel 4 node and is also Intel's first client chip to use EUV lithography. Intel 4 is a key part of Intel's IDM 2.0 strategy, which aims to achieve parity by 2024 and process leadership by 2025. We have already written a piece detailing the Intel 4 node in great detail, which can be found below:
Intel 4 Process Node In Detail: 2x Density Scaling, 20% Improved Performance
Intel 4 uses extreme ultraviolet (EUV) lithography, a highly efficient manufacturing technique that simplifies manufacturing, improving yield and area scaling. Not only is EUV, along with Intel 4, which is designed to scale out for better power efficiency, but it's also the precursor for Intel to switch things over to their Intel 3 process, which is still being developed.

According to Intel's '5 nodes in 4 years' goal within the roadmap, Intel 3 is stated to be manufacturing-ready in H2 of 2023. What's interesting about the cadence of Intel 3 in the roadmap is that Intel 3 is design-compatible with Intel 4, and as such, Intel 3 is designed to be the long-lived node with EUV lithography.

One of the primary benefits of Intel 4 is its area scaling capabilities. The Intel 4 process offers 2X the area scaling for high-performance logic libraries compared with the previous Intel 7 process node – a process which wasn't only troublesome through its exceedingly long development cycle, but yields were not the greatest. Having the ability to scale out in such a way is vital for fitting more and more transistors on a chip, which should theoretically improve the overall performance and efficiency of the silicon. Intel 4 is also optimized for high-performance computing applications and supports both low-voltage (<0.65V) and high-voltage (>1.1V) operations. Intel claims that having this flexibility results in more than 20% performance in iso-power performance over Intel 7, and the technology also incorporates high-density Metal-Insulator-Metal (MIM) capacitors, which Intel claims make power delivery to the chip superior.
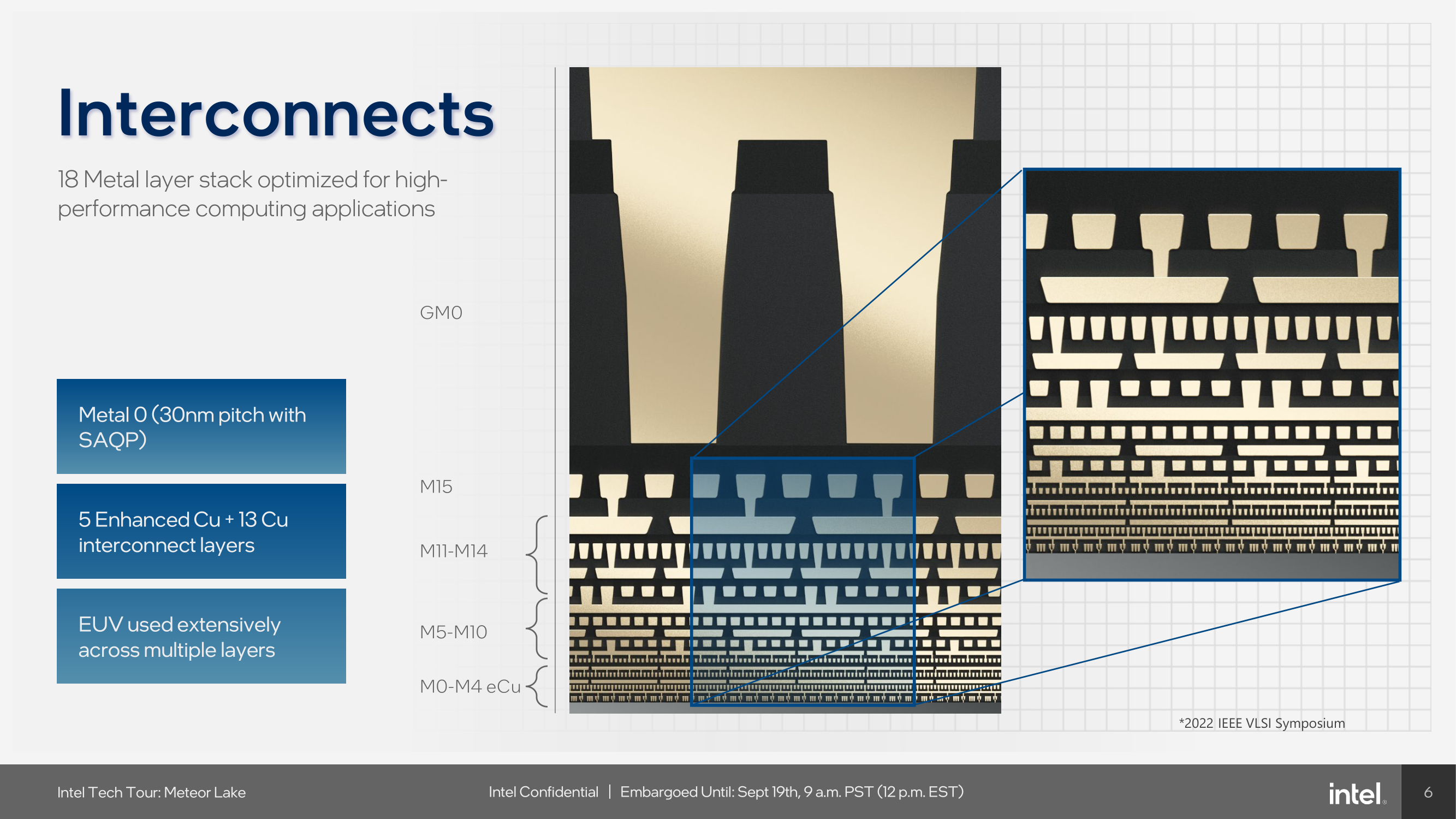
Through Intel 4 with EUV, Intel uses a 30 mm fin pitch with self-aligned quad patterning (SAQP) and a 50 nm tungsten gate pitch, scaled down by 0.83x from 54/60 nm on Intel 7. The M0 pitch is also down by 0.75x to 30 nm from 40 nm, and the HP library height has been reduced greatly from 408 in Intel 7 to 240 nm on Intel 4, a scaling of 0.59x. Moving from a 4 fin to 3 fin allocation means that Meteor Lake on Intel 4 has a tighter gate spacing than Intel 7.
One key new introduction to Intel 4 is the materials used, with Intel using what it calls 'Enhanced Copper'. Although Intel hasn't disclosed the specific percentage of the mixture, Enhanced Copper is essentially copper (Cu) adorned with cobalt (Co) and is designed to eliminate high resistance and high volume barriers. The combined metallurgy of copper and cobalt is used on layers M0 to M4, while layers M5 to M15 are made from copper using different pitches ranging from 50 nm up to 280 nm.
| Comparing Intel 4 to Intel 7 | |||
| Intel 4 | Intel 7 | Change | |
| Fin Pitch | 30 nm | 34 nm | 0.88 x |
| Contact Gate Poly Pitch | 50 nm | 54/60 nm | 0.83 x |
| Minimum Metal Pitch (M0) | 30 nm | 40 nm | 0.75 x |
| HP Library Height | 240h | 408h | 0.59 x |
| Area (Library Height x CPP) | 12K nm2 | 24.4K nm2 | 0.49 x |
Using Extreme Ultraviolet (EUV) lithography on Intel 4 represents a major progressive advancement in semiconductor fabrication. Accomplished by using x-rays with a wavelength of around 13.5 nanometers (generated by zapping tin with a laser, no less), EUV lithography significantly improves and optimizes the photolithographic process, allowing for enhanced resolution and pattern fidelity metrology. The technology requires specialized equipment, including high-precision optics and vacuum chambers, with a single EUV lithographic system costing around $150 million (as per Reuters).
When it comes to using manufacturing chips, there are different levels of patterning, both single and multi-patterning. Using EUV allows Intel to reduce the number of masks and steps in the fabrication process, with up to 20% fewer masks on Intel 4 than Intel 7 by replacing multi-patterning steps a single EUV layer. While each patterning level presents its own unique challenges, EUV allows for a single pattern to use just one exposure to etch out. This means that production can be increased and flow faster throughout the process. Opting for multi-patterning means more cost and higher variability. Another advantage of using a single-pattern EUV process also reduces the number of defects within the silicon.
Despite the substantial capital and operational expenditures, the technology offers compelling advantages, such as a reduction in mask count by 20% and a decrease in process steps by 5% for Intel 4. These efficiencies contribute to superior area scaling and yield optimization and put EUV lithography as a cornerstone in Intel's processor roadmap as they try to achieve leadership. It also synergizes with Advanced Packaging Technologies (APT) like Embedded Multi-die Interconnect Bridge (EMIB) and is combined with Foveros 3D packaging, further ensuring its role as a progressive technology in semiconductor and chip manufacturing.








107 Comments
View All Comments
tipoo - Tuesday, September 19, 2023 - link
Is anyone at AT planning on deep diving the A17 Pro?Ryan Smith - Tuesday, September 19, 2023 - link
At the moment, no. I do not have a mobile editor to work on such projects.FWhitTrampoline - Tuesday, September 19, 2023 - link
Oh no that's bad news as Apple appears to have gone even wider with the A17 P cores than even the A14/Firestorm with decode resources on A17/P core, if the Apple promotional material is correct!Maybe Chipsandcheese will look at A17's P core design and with some Micro-benchmarks as well.
tipoo - Tuesday, September 19, 2023 - link
Yeah that's too bad, it looks like the e-cores got a bigger bump than the p-cores but they didn't advertise it with how strangely they mentioned itFWhitTrampoline - Wednesday, September 20, 2023 - link
The slide from Intel on its Crestmont E core design(Block Diagram) does not look that much different from Gracemont's block diagram and Redwood Cove(Block Diagram) core design still appears to be a 6 wide Instruction Decoder design and so Similar to Golden Cove but there needs to be more info concerning Micro-Op issue rates and other parts of Redwood Cove's core design.GeoffreyA - Thursday, September 21, 2023 - link
It's hard to see the instruction decoders being increased all that much, because of their power burden in x86.ikjadoon - Tuesday, September 19, 2023 - link
>As expected, Meteor Lake brings generational IPC gains through the new Redwood Cove cores.Redwood Cove does not have any IPC gain, I believe. Is there a citation or slide regarding this?
This will be now the third Intel CPU generation with 0% to 1% IPC gains in their P-cores.
Gavin Bonshor - Tuesday, September 19, 2023 - link
Intel confirmed to me Redwood Cove would have IP gains over Raptor Cove. When I get back (been sat at a PC a lot the last few days), I'll grab it for youkwohlt - Tuesday, September 19, 2023 - link
There's so many changes in MTL, it would make sense to just save a new P core uArch for next gen. Especially when clockspeed/watt is going up a decent amount, so it's not like perf/watt is stagnating.GeoffreyA - Thursday, September 21, 2023 - link
I think they've been following the old tick-tock system, Sunny and Golden Cove being the tocks, and Willow and Raptor the ticks. So, it's possible that Redwood would bring some proper changes.