The Impact of Disruptive Technologies on the Professional Storage Market
by Johan De Gelas on August 5, 2013 9:00 AM EST- Posted in
- IT Computing
- SSDs
- Enterprise
- Enterprise SSDs
Nutanix: No More SAN
It is not a secret that even though a SAN comes with all the virtues of centralized data, network storage comes with a network bandwidth and latency penalty. By simply attaching a flash array directly to a system (DAS), we can measure the extra latency compared to SAN (Storage Area Network). It amounts to between 0.3 and 0.8 ms depending on whether you use Fibre Channel or iSCSI over copper wires.

So the minimal latency was 50% to 100% higher in a lightly loaded SAN than when the same SSD was running inside the server. However, this was the minimal latency. This can quickly grow to several milliseconds when the network load goes up.
Nutanix believes that virtualized servers should use local storage, clustered together in a virtual storage pool. Each of the virtual machines connects to a storage VM. That storage VM is typically an iSCSI target inside a VM, also called a VSA or Virtual Storage Appliance. The VSA on each server node are clustered together by the Nutanix Distributed File System (NDFS). NDFS makes sure that if one node dies, the other nodes are still able to access the necessary files to run.
.jpg)
The VSA also leverages the latest flash technology. The most accessed data is on a Fusion-IO or Intel S3700 SSDs, depending on the Nutanix node model. The “colder” (not frequently accessed) data is automatically transferred to the SATA terabyte disks. It's basically another level of caching, only with larger data caches than we see in the desktop world.

Using what seems to be a Supermicro Twin or Twin² chassis, even an entry level four node Nutanxi NX-3050 should support up to 400 virtual desktops with a power consumption of about 1.1 KW. Compare this with your typical SAN array that typically needs 700W just for one midrange array, and you probably need several expansion modules before you can even think about supporting 400 virtual desktops.
Unfortunately, we cannot verify the claims of Nutanix right now, but our experience tells us that from a power and performance point of view it will be very hard for the typical "server plus SAN infrastructure" to beat the much simpler “integrate everything inside a dense server” platform. The only disadvantage is that the number of DIMM slots inside such server nodes is limited. That is why even the largest Nutanix hosts do not support more than 256GB per node, which might be a limitation in some virtualization environments.
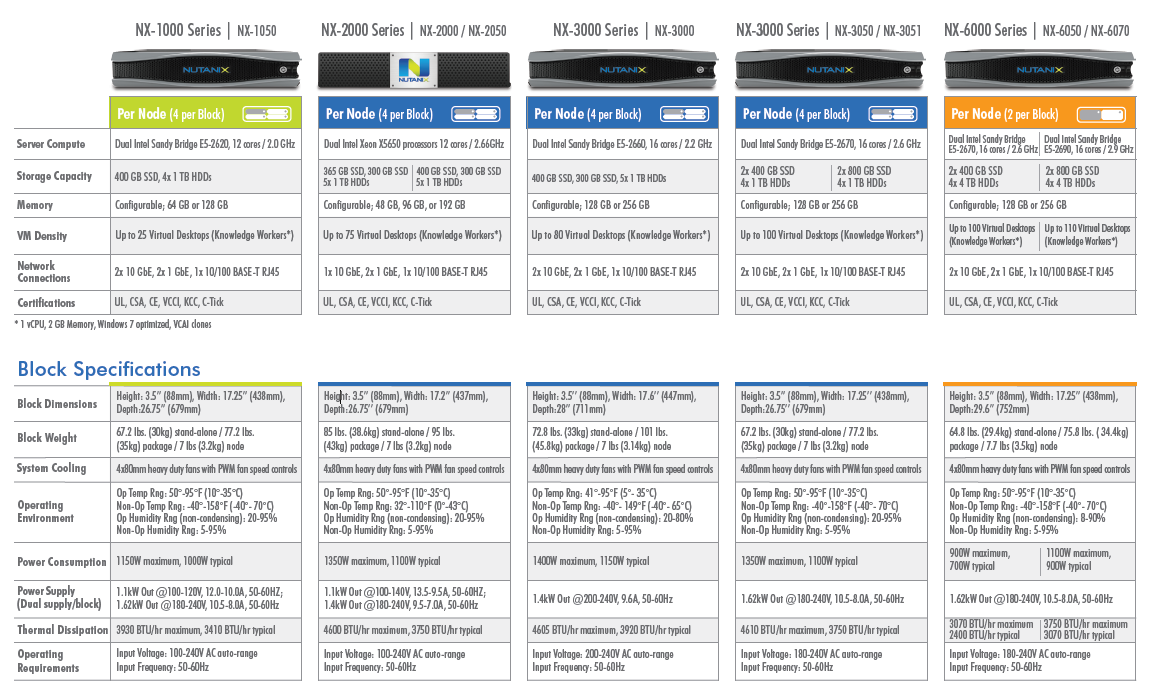
Starting at $22000 per node, the Nutanix nodes are hardly cheap, but since you don’t need a SAN the total investment is a lot lower than the traditional approach, especially for virtual desktops. Nutanix seems to have convinced quite a few people as it claims it is the fastest growing IT infrastructure startup ever, with an $80 million annual run rate. Now they just need to prove they have the reliability and support infrastructure to win over additional customers.








60 Comments
View All Comments
jhh - Wednesday, August 7, 2013 - link
And Advanced/SDDC/Chipkill ECC, not the old-fashioned single-bit correct/multiple bit detect. The RAM on the disk controller might be small enough for this not to matter, but not on the system RAM.tuxRoller - Monday, August 5, 2013 - link
Amplidata's dss seems like a better, more forward looking alternative.Sertis - Monday, August 5, 2013 - link
The Amplistore design seems a bit better than ZFS. ZFS has a hash to detect bit rot within the blocks, while this stores FEC coding that can potentially recover the data within that block without calculating it based on parity from the other drives on the stripe and the I/O that involves. It also seems to be a bit smarter on how it distributes data by allowing you to cross between storage devices to provide recovery at the node level while ZFS is really just limited to the current pool. It has various out of band data rebalancing which isn't really present in ZFS. For example, add a second vdev to a zpool when it's 90% full and there really isn't a process to automatically rebalance the data across the two pools as you add more data. The original data stays on that first vdev, and new data basically sits in the second vdev. It seems very interesting, but I certainly can't afford it, I'll stick with raidz2 for my puny little server until something open source comes out with a similar feature set.Seemone - Tuesday, August 6, 2013 - link
Are you aware that with ZFS you can specify the number of replicas each data block should have on a per-filesystem basis? ZFS is indeed not very flexible on pool layout and does not rebalance things (as of now), but there's nothing in the on-disk data structure that prevent this. This means it can be implemented and would be applicable on old pools in a non disruptive way. ZFS, also, is open source, its license is simply not compatible with GPLv2, hence ZFS-On-Linux separate distribution.Brutalizer - Tuesday, August 6, 2013 - link
If you want to rebalance ZFS, you just copy the data back and forth and rebalancing is done. Assume you have data on some ZFS disks in a ZFS raid, and then you add new empty discs, so all data will sit on the old disks. To spread the data evenly to all disks, you need to rebalance the data. Two ways:1) Move all data to another server. And then move back the data to your ZFS raid. Now all data are rebalanced. This requires another server, which is a pain. Instead, do like this:
2) Create a new ZFS filesystem on your raid. This filesystem is spread out on all disks. Move the data to the new ZFS filesystem. Done.
Sertis - Thursday, August 8, 2013 - link
I'm definitely looking forward to these improvements, if they eventually arrive. I'm aware of the multiple copy solution, but if you read the Intel and Amplistore whitepapers, you will see they have very good arguments that their model works better than creating additional copies by spreading out FEC blocks across nodes. I have used ZFS for years, and while you can work around the issues, it's very clear that it's no longer evolving at the same rate since Oracle took over Sun. Products like this keep things interesting.Brutalizer - Tuesday, August 6, 2013 - link
Theory is one thing, real life another. There are many bold claims and wonderful theoretical constructs from companies, but do they hold up to scrutiny? Researchers injected artificially constructed errors in different filesystems (NTFS, Ext3, etc), and only ZFS detected all errors. Researchers have verified that ZFS seems to combat data corruption. Are there any research on Amplistore's ability to combat datacorruption? Or do they only have bold claims? Until I see research from a third part, independent part, I will continue with the free open source ZFS. CERN is now switching to ZFS for tier-1 and tier-2 long time term storage, because vast amounts of data _will_ have data corruption, CERN says. Here are research papers on data corruption on NTFS, hardware raid, ZFS, NetApp, CERN, etc:http://en.wikipedia.org/wiki/ZFS#Data_integrity
For instance, Tegile, Coraid, GreenByte, etc - are all storage vendors that offers PetaByte Enterprise servers using ZFS.
JohanAnandtech - Tuesday, August 6, 2013 - link
Thanks, very helpful feedback. I will check the paper outmikato - Thursday, August 8, 2013 - link
And Isilon OneFS? Care to review one? :)bitpushr - Friday, August 9, 2013 - link
That's because ZFS has had a minimal impact on the professional storage market.