NVIDIA Announces Tesla M40 & M4 Server Cards - Data Center Machine Learning
by Ryan Smith on November 10, 2015 9:00 AM EST- Posted in
- GPUs
- Tesla
- Datacenter
- NVIDIA
- Machine Learning

Slowly but steadily NVIDIA has been rotating in Maxwell GPUs into the company’s lineup of Tesla server cards. Though Maxwell is not well-suited towards the kind of high precision HPC work that the Tesla lineup was originally crafted for, Maxwell is plenty suitable for just about every other server use NVIDIA can think of. And as a result the company has been launching what’s best described as new breeds of Maxwell cards in the last few months.
After August’s announcement of the Tesla M60 and M6 cards – with a focus on VDI and video encoding – NVIDIA is back today for the announcement of the next set of Tesla cards, the M40 and the M4. In what the company is dubbing their “hyperscale accelerators,” NVIDIA is launching these two cards with a focus on capturing a larger portion of the machine learning market.

| NVIDIA Tesla Family Specification Comparison | ||||||
| Tesla M40 | Tesla M4 | Tesla M60 | Tesla K40 | |||
| Stream Processors | 3072 | 1024 | 2 x 2048 (4096) |
2880 | ||
| Boost Clock(s) | ~1140MHz | ~1075MHz | ~1180MHz | 810MHz, 875MHz | ||
| Memory Clock | 6GHz GDDR5 | 5.5GHz GDDR5 | 5GHz GDDR5 | 6GHz GDDR5 | ||
| Memory Bus Width | 384-bit | 128-bit | 2 x 256-bit | 384-bit | ||
| VRAM | 12GB | 4GB | 2 x 8GB (16GB) |
12GB | ||
| Single Precision (FP32) | 7 TFLOPS | 2.2 TFLOPS | 9.7 TFLOPS | 4.29 TFLOPS | ||
| Double Precision (FP64) | 0.21 TFLOPS (1/32) | 0.07 TFLOPS (1/32) | 0.3 TFLOPS (1/32) | 1.43 TFLOPS (1/3) | ||
| Transistor Count | 8B | 2.94B | 2x 5.2B | 7.1B | ||
| TDP | 250W | 50W-75W | 225W-300W | 235W | ||
| Cooling | Passive | Passive (Low Profile) |
Active/Passive | Active/Passive | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| GPU | GM200 | GM206 | GM204 | GK110 | ||
| Target Market | Machine Learning | Machine Learning | VDI | Compute | ||
First let’s quickly talk about the cards themselves. The Tesla M40 marks the introduction of the GM200 GPU to the Tesla lineup, with NVIDIA looking to put their best single precision (FP32) GPU to good use. This is a 250 Watt full power and fully enabled GM200 card – though with Maxwell this distinction loses some meaning – with NVIDIA outfitting the card with 12GB of GDDR5 VRAM clocked at 6GHz. We know that Maxwell doesn’t support on-chip ECC for the RAM and caches, but it’s not clear at this time whether soft-ECC is supported for the VRAM. Otherwise, with the exception of the change in coolers this card is a spitting image of the consumer GeForce GTX Titan X.

Joining the Tesla M40 is the Tesla M4. As hinted at by its single-digit product number, the M4 is a small, low powered card. In fact this is the first Tesla card to be released in a PCIe half-height low profile form factor, with NVIDIA specifically aiming for dense clusters of these cards. Tesla M4 is based on GM206 – this being the GPU’s first use in a Tesla product as well – and is paired with 4GB of GDDR5 clocked at 5GHz. NVIDIA offers multiple power/performance configurations of the M4 depending on server owner’s needs, ranging from 50W to 75W, with the highest power mode rated to deliver up to 2.2TFLOPS of FP32 performance.

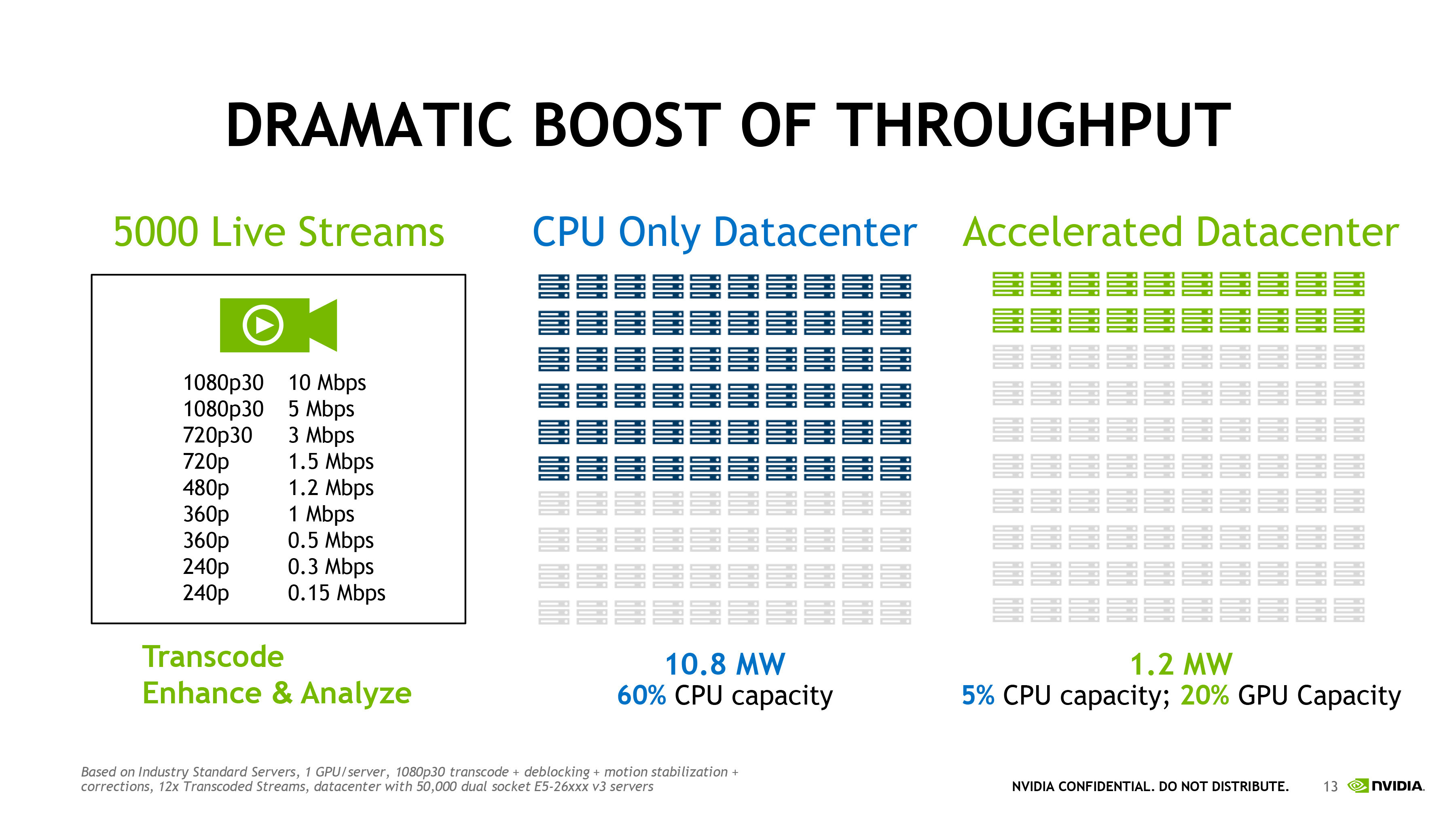
Both the Tesla M40 and M4 are being pitched at the machine learning market, which has been a strong focus for NVIDIA since the very start of the year. The company believes that machine learning is the next great frontier for GPUs, capitalizing on neural net research that has shown GPUs to be capable of both quickly training and quickly executing neural nets. Neural nets in turn are increasingly being used as more efficient means for companies to process vast amounts of audio & video data (e.g. the Facebooks of the world).
To that end we have seen the company focus on machine learning in the automotive sector with products such as the Drive PX system and lay out their long-term plans for machine learning with the forthcoming Pascal architecture at GTC 2015. In the interim then we have the Tesla M40 and Tesla M4 for building machine learning setups with NVIDIA’s current-generation architecture.

Given their performance and power profiles, Tesla M40 and M4 are intended to split the machine learning market on the basis of training versus execution The powerful M40 being well-suited for quicker training of neural nets and other systems, while the more compact M4 is well-suited for dense clusters of systems actually executing various machine learning tasks. Note that it’s interesting that NVIDIA is pitching the M40 and not the more powerful M60 for training tasks; as NVIDIA briefly discussed among their long-term plans at GTC 2015, current training algorithms don’t scale very well beyond a couple of GPUs, so users are better off with a couple top-tier GM200 GPUs than a larger array of densely packed GM204 GPUs. As a result the M40 occupies an interesting position as the company’s top Tesla card for machine learning tasks that aren’t trivially scalable to many GPUs.

Meanwhile, along with today’s hardware announcement NVIDIA is also announcing a new software suite to tie together their hyperscale ambitions. Dubbed the “NVIDIA Hyperscale Suite,” the company is putting together software targeted at end-user facing web services. Arguably the lynchpin of the suite is NVIDIA’s GPU REST Engine, a service for RESTful APIs to utilize the GPU, and in turn allowing web services to easily access GPU resources. NVIDIA anticipates the GPU REST Engine enabling everything from search acceleration to image classification, and to start things off they are providing the NVIDIA Image Compute Engine, a REST-capable service for GPU image resizing. Meanwhile the company is also be providing their cuDNN neural net software as part of the suite, and versions of FFmpeg with support for NVIDIA’s hardware video encode and decode blocks to speed up video processing and transcoding.
Wrapping things up, as is common with Tesla product releases, today’s announcements will predate the hardware itself by a bit. NVIDIA tells us that the Tesla M40 and the hyperscale software suite will be available later this year (with just over a month and a half remaining). Meanwhile the Tesla M4 will be released in Q1 of 2016. NVIDIA has not announced card pricing at this time.













24 Comments
View All Comments
close - Tuesday, November 10, 2015 - link
FP64 performance makes me cry...tipoo - Tuesday, November 10, 2015 - link
Didn't they make FP16 in large part for deep learning? I'm no expert in this field but it seems they were saying that you not only don't need double precision for it, you may need less than single precision and can use half precision FP16 for deep learning. Which is what these cards are for, so it may be moot to complain about FP64 being so cut down.Loki726 - Tuesday, November 10, 2015 - link
Yes, high precision is not a requirement for deep learning. Many models actually run in 8-bit fixed point.p1esk - Tuesday, November 10, 2015 - link
Which models run in 8-bit?extide - Tuesday, November 10, 2015 - link
Well, that's what the GK110 is for -- if you need FP64, then these cards (or any Maxwell cards) are not for you.HighTech4US - Tuesday, November 10, 2015 - link
As a baby you do cry a lot. Often about nothing. This being the case again.As for FP64 you do not need it (and it would hurt) deep learning. In fact FP16 is coming to accelerate it even more.
close - Tuesday, November 10, 2015 - link
Do we know each other? Or do you just roam the interwebs throwing trash with one hand and copying what others say with the other?A quick search by your (very inaccurate) username revealed that both of the above are true.
303rob - Thursday, November 12, 2015 - link
@HighTech4US for the record babies never ever cry about nothing you fucking imbeceal, i joined purely to say that to you....such is the gargantuan size of your error, one can only asume you are as thoughtless as your commentnico_mach - Tuesday, November 10, 2015 - link
Kind of irrelevant, but they have the best branding in the tech world: Titan, Tesla, Shield, CUDA. GeForce, G-SYNC and Grid aren't imaginative, but there are no stinkers in that list, which is shocking. It's as good as the best car makers, which is kind of amazing.tipoo - Tuesday, November 10, 2015 - link
G-Sync came the closest to bad. Imagine if they went N-Sync instead :P